")
")
Embeddings & Reranking
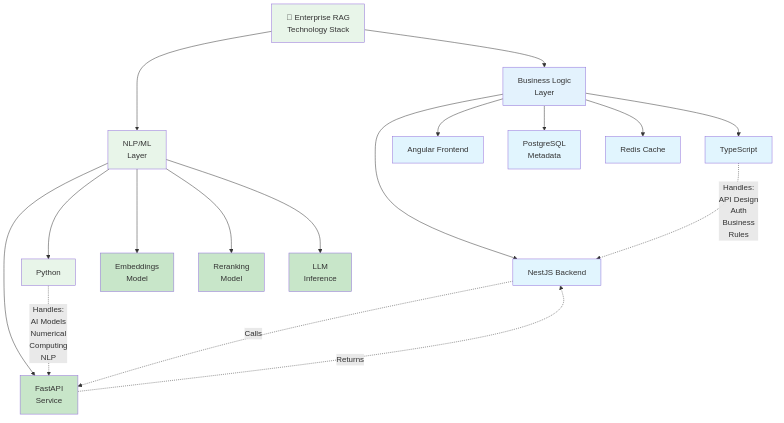
Why I Build Embedding Generation as a Microservice
Vector embeddings are the heart of semantic search. They're the mechanism that transforms meaning into mathematical space. But generating them isn't free—it requires computational overhead, model loading, and careful optimization.
Enter FastAPI: a lightweight Python framework perfectly suited to building specialized NLP services. Rather than embedding generation happening inside n8n (bottlenecking the orchestration engine), I built a dedicated FastAPI service that handles embeddings, reranking, and model management.
This article explores why Python is the right choice for NLP, how FastAPI architecture serves billions of inference requests, and how configuration-driven model selection keeps your RAG system flexible.
Why Python for NLP? The Short Answer
When it comes to machine learning and natural language processing, Python isn't just popular—it's dominant.
The ecosystem matters:
- Hugging Face - 1M+ pre-trained models (embeddings, classifiers, rerankers)
- sentence-transformers - SOTA embedding models, one-line inference
- transformers library - PyTorch/TensorFlow integration, easy fine-tuning
- ONNX Runtime - Deploy models with minimal dependencies
The alternative? Building embedding inference in Node.js (NestJS) or Go? Possible, but you're:
- Rewriting existing ML libraries from scratch (why?)
- Losing community support and pre-trained models
- Dealing with tensor operations manually
- Spending weeks on what Python does in days
The pragmatic choice: Python for compute-intensive tasks (embeddings, reranking), other services for everything else (NestJS for business logic, Angular for UI, n8n for orchestration).
Why FastAPI Specifically?
Python has many frameworks: Django, Flask, FastAPI, Chalice, Quart. For a microservice that handles high-throughput API requests, FastAPI stands out:
FastAPI advantages:
- Async by default - Handle 1000s of concurrent requests without thread overhead
- Auto-generated OpenAPI docs - Self-documenting APIs
- Type hints - Built-in validation (Pydantic), no manual schema checks
- Performance - Nearly as fast as Go/Rust web frameworks
- Simplicity - Minimal boilerplate, focus on business logic
Concrete example:
@app.post("/embed")
async def embed_text(request: EmbedRequest):
# Pydantic validates input automatically
# Async means we can handle other requests while this one processes
return await compute_embeddings(request.texts)
Why not Flask? Synchronous-only, slower for concurrent requests.
Why not Django? Heavyweight, too many features for a simple API.
The Three Core Endpoints
Your FastAPI service exposes three endpoints (called from n8n workflows):
1. POST `/embed` - Generate Vector Embeddings
Purpose: Convert text to 768-dimensional vectors
Input:
{
"texts": ["What is the vacation policy?", "HR handbook chapter 3"],
"model": "sentence-transformers/all-MiniLM-L6-v2",
"normalize": true
}
Output:
{
"embeddings": [
[-0.042, 0.156, -0.089, ..., 0.651], // first text
[0.103, -0.051, 0.248, ..., -0.172] // second text
],
"model": "all-MiniLM-L6-v2",
"model_dim": 768,
"inference_time_ms": 45
}
Key parameters:
texts: Array of strings to embed (batch processing for efficiency)model: Which embedding model to use (configurable)normalize: Optional L2 normalization (for cosine similarity optimization)
Performance note: Batching 10 texts together is ~5x faster than 10 separate requests.
2. POST `/rerank` - Improve Search Result Relevance
Purpose: Re-score retrieved results based on relevance to the query
Why? Vector similarity is good but not perfect. A reranker uses cross-encoder models to score query-document pairs more accurately.
Input:
{
"query": "How many vacation days do I get?",
"documents": [
"You get 20 vacation days per year",
"You can request time off here",
"The parking policy is in section 5"
],
"top_k": 2,
"model": "cross-encoder/ms-marco-MiniLM-L-6-v2"
}
Output:
{
"ranked": [
{"doc": "You get 20 vacation days per year", "score": 0.94},
{"doc": "You can request time off here", "score": 0.72}
],
"model": "cross-encoder/ms-marco-MiniLM-L-6-v2",
"inference_time_ms": 120
}
When to use reranking:
- Top_k results from Qdrant are close in similarity (need better discrimination)
- Query is complex or ambiguous
- You can afford 50-200ms extra latency for better accuracy
When to skip: Simple queries, performance-critical paths (e.g., real-time chat with sub-100ms SLA).
3. GET `/config` - Query Service Configuration
Purpose: Report what models are available and service status
Output:
{
"service": "RAG NLP Engine",
"embedding_models": [
{
"name": "all-MiniLM-L6-v2",
"dimensions": 384,
"inference_time_ms": 25,
"languages": ["en", "multilingual"]
},
{
"name": "all-mpnet-base-v2",
"dimensions": 768,
"inference_time_ms": 45,
"languages": ["en", "multilingual"]
},
{
"name": "multilingual-e5-large",
"dimensions": 1024,
"inference_time_ms": 80,
"languages": 100+
}
],
"reranker_models": [
{
"name": "cross-encoder/ms-marco-MiniLM-L-6-v2",
"inference_time_ms": 120
}
],
"gpu_available": true,
"gpu_model": "NVIDIA A40",
"memory_usage_mb": 2048,
"status": "healthy"
}
Why expose config? NestJS backend queries this at startup to display available models in the admin UI. Users can choose which model to use per query.

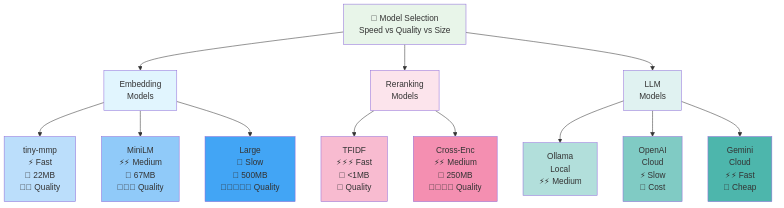
Model Selection: Trade-offs and Strategy
Not all embedding models are equal. They differ in speed, quality, and language support:
Lightweight vs High-Quality:
Fast & Small:
- all-MiniLM-L6-v2 (384 dims, 25ms, 22MB)
- Good for: High QPS, cost-sensitive deployments
Medium:
- all-mpnet-base-v2 (768 dims, 45ms, 430MB)
- Good for: Balanced accuracy/speed
High-Quality:
- multilingual-e5-large (1024 dims, 80ms, 2GB)
- Good for: Maximum accuracy, multilingual support
Language considerations:
English-optimized:
- Faster, smaller, better accuracy on English
- all-MiniLM-L6-v2, all-mpnet-base-v2
Multilingual:
- Support 50+ languages in one model
- multilingual-e5-large, xlm-roberta-base
- Tradeoff: Larger, slower, but one model for all languages
Your pragmatic approach: Start with all-MiniLM-L6-v2 (fast, good enough). If accuracy becomes a problem, upgrade to all-mpnet-base-v2. If your documents are multilingual, jump to multilingual-e5-large.
Key insight: Model selection is configuration, not code:
{
"embeddings": {
"default_model": "all-MiniLM-L6-v2",
"reranker_model": "cross-encoder/ms-marco-MiniLM-L-6-v2",
"batch_size": 32,
"use_gpu": true
}
}
Change the JSON, restart the service. No code changes.
GPU vs CPU: The Performance Reality
CPU path:
- Inference on Intel Xeon: ~80-200ms per query
GPU path:
- NVIDIA A40: ~15-30ms per query
- NVIDIA T4: ~30-50ms per query
- NVIDIA A100: ~5-10ms per query
GPU advantage multiplier: 5-15x faster
But GPUs cost money. When does it make sense?
GPU is worth it when:
- QPS > 100 (you're doing queries constantly)
- Latency SLA < 100ms (you need speed)
- Cost of GPU is offset by fewer CPU cores (or cloud cost)
CPU is fine when:
- QPS < 50 (queries are bursty, not constant)
- Latency SLA > 200ms (users can wait)
- No GPU budget
Your setup: If you have a GPU available, FastAPI auto-detects and uses it. Otherwise, falls back to CPU. Configuration-driven.
# FastAPI startup
if torch.cuda.is_available():
device = "cuda"
else:
device = "cpu"
model = SentenceTransformer("all-MiniLM-L6-v2").to(device)
Optimization Patterns: Making It Fast
Batching
Technique: Group multiple embedding requests
Without batching:
Request 1: text → embed → 45ms
Request 2: text → embed → 45ms
Request 3: text → embed → 45ms
Total: 135ms
With batching:
Batch [text1, text2, text3] → embed → 50ms (matrix multiplication is parallelized)
Total: 50ms
Speedup: 2.7x
n8n's capability: Loop through documents, accumulate 32 at a time, send batch to FastAPI.
Model Caching
Without caching:
Request 1: Load model (2GB, 500ms) + embed → 545ms
Request 2: Load model + embed → 545ms
Request 3: Load model + embed → 545ms
With caching:
Request 1: Load model (500ms) + embed → 545ms
Request 2: Use cached model + embed → 45ms
Request 3: Use cached model + embed → 45ms
FastAPI loads models on startup, keeps them in memory. Subsequent requests reuse loaded models.
Async Request Handling
Without async (Flask):
Request 1 arrives → Process (100ms) → Response
Request 2 arrives → Wait for Request 1 to finish → Process (100ms) → Response
Total for 2 requests: 200ms
With async (FastAPI):
Request 1 arrives → Start processing (non-blocking)
Request 2 arrives → Start processing (non-blocking)
Both complete in ~100ms (parallelized)
Total for 2 requests: ~110ms
Speedup: 1.8x
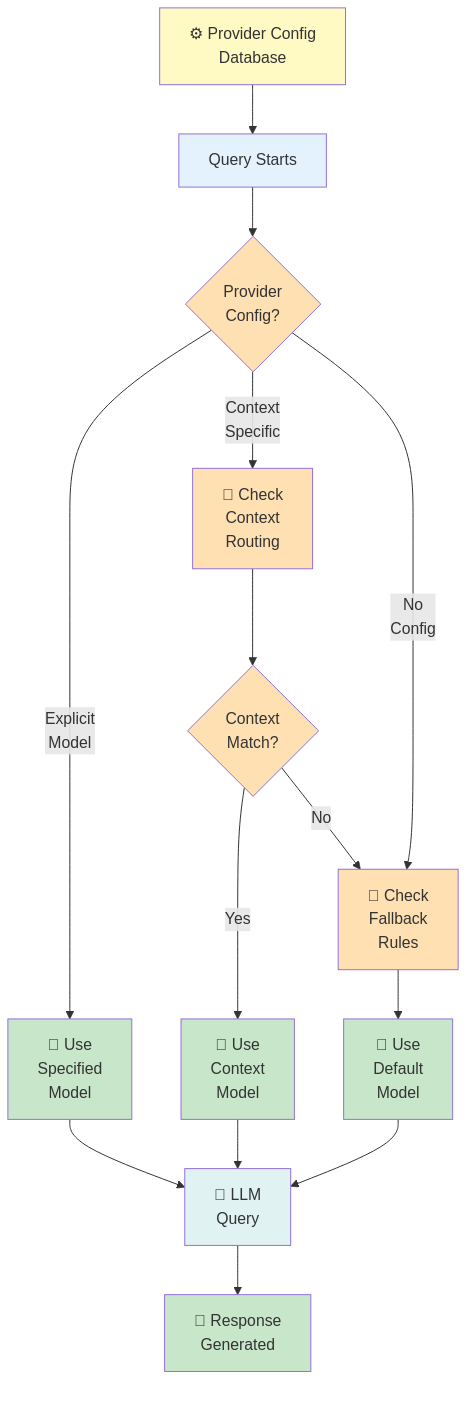
Configuration-Driven Model Switching
Your RAG system doesn't hardcode model choices. Instead, the backend (NestJS) stores model configuration per context:
Context: "policy_documents"
├─ embedding_model: "all-mpnet-base-v2"
├─ reranker_model: "cross-encoder/qnli"
└─ top_k: 10
Context: "technical_docs"
├─ embedding_model: "multilingual-e5-large"
├─ reranker_model: null (skip reranking for speed)
└─ top_k: 5
n8n reads this configuration and calls the appropriate endpoints:
n8n workflow:
1. Get context config from NestJS
2. Call FastAPI /embed with config.embedding_model
3. Search Qdrant
4. If config.reranker_model: Call FastAPI /rerank
5. Continue...
Result: Different contexts use different strategies, all orchestrated by n8n, all configurable in NestJS.
Integration with n8n: The Contract
n8n doesn't know (or care) about PyTorch, transformers, or CUDA. It just knows:
POST http://fastapi:8000/embed
Content-Type: application/json
{
"texts": [...list of strings...],
"model": "all-MiniLM-L6-v2",
"normalize": true
}
→ 200 OK
{
"embeddings": [...list of vectors...],
"inference_time_ms": 45
}
This is the contract. As long as FastAPI honors it, n8n doesn't care what's inside.
Why this matters: You could replace FastAPI with Go/Rust service tomorrow, change the endpoint URL in n8n, and everything works. Same orchestration, different backend.
Conclusion: Specialized Services, Orchestrated Cleanly
FastAPI's role in your RAG system is focused: generate embeddings, rerank results, expose configuration. It's not trying to be "the API" for everything (that's NestJS). It's not trying to be "the orchestrator" (that's n8n). It does one thing well.
This specialization is what makes RAG systems maintainable:
- NestJS handles business logic, authentication, permissions
- FastAPI handles compute-intensive NLP tasks
- n8n orchestrates them
- Qdrant stores vectors
- PostgreSQL stores metadata
Each tool has a clear responsibility. Swap implementations without breaking the system.
---
GitHub:
- RAD System (open-source): https://github.com/msbragi/rad-system
- RAG System (technology overview & examples — source not published): https://github.com/msbragi/RAG-System-Dist
Built with: FastAPI (microservice), sentence-transformers (embeddings), PyTorch (inference), asyncio (concurrency), Pydantic (validation).