")
")
Embeddings & Reranking
Perché Costruire la Generazione di Embeddings come Microservizio
Gli embeddings vettoriali sono il cuore della ricerca semantica. Sono il meccanismo che trasforma il significato nello spazio matematico. Ma generarli non è gratis—richiede overhead computazionale, caricamento di modelli, e ottimizzazione attenta.
Ecco FastAPI: un framework Python leggero perfettamente adatto a costruire servizi NLP specializzati. Piuttosto che la generazione di embeddings dentro n8n (collo di bottiglia del motore di orchestrazione), ho costruito un servizio FastAPI dedicato che gestisce embeddings, reranking, e gestione dei modelli.
Questo articolo esplora perché Python è la scelta giusta per NLP, come l'architettura FastAPI serve miliardi di richieste di inferenza, e come la selezione di modelli basata su configurazione mantiene il tuo sistema RAG flessibile.
Perché Python per NLP? La Risposta Breve
Quando si tratta di machine learning ed elaborazione del linguaggio naturale, Python non è solo popolare—è dominante.
L'ecosistema è importante:
- Hugging Face - 1M+ modelli pre-addestrati (embeddings, classificatori, rerankers)
- sentence-transformers - Modelli embedding SOTA, inferenza con una riga di codice
- libreria transformers - Integrazione PyTorch/TensorFlow, fine-tuning facile
- ONNX Runtime - Deploy modelli con dipendenze minimali
L'alternativa? Costruire inferenza di embeddings in Node.js (NestJS) o Go? Possibile, ma:
- Riscrivere librerie ML da zero (perché?)
- Perdere supporto della comunità e modelli pre-addestrati
- Gestire operazioni tensoriali manualmente
- Spendere settimane in quello che Python fa in giorni
La scelta pragmatica: Python per task computazionali intensivi (embeddings, reranking), altri servizi per tutto il resto (NestJS per la logica di business, Angular per UI, n8n per orchestrazione).
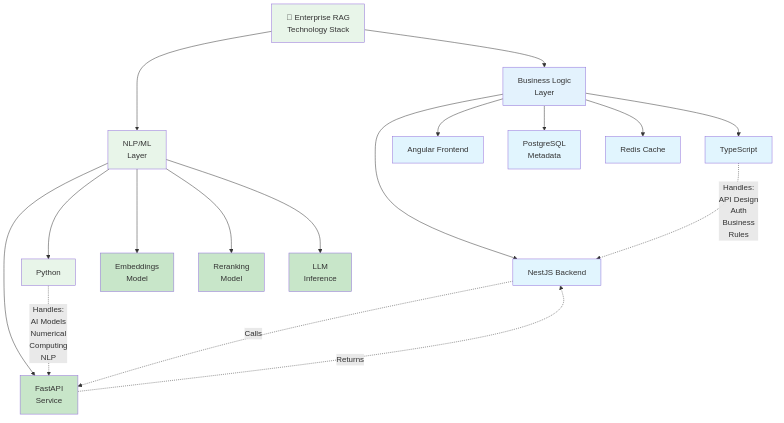
Perché FastAPI Specificamente?
Python ha molti framework: Django, Flask, FastAPI, Chalice, Quart. Per un microservizio che gestisce richieste API ad alto throughput, FastAPI si distingue:
Vantaggi FastAPI:
- Async per default - Gestisci migliaia di richieste concorrenti senza overhead di thread
- Docs OpenAPI auto-generati - API auto-documentate
- Type hints - Validazione built-in (Pydantic), nessun controllo di schema manuale
- Performance - Quasi veloce quanto i framework web Go/Rust
- Semplicità - Boilerplate minimale, focus sulla logica di business
Esempio concreto:
@app.post("/embed")
async def embed_text(request: EmbedRequest):
# Pydantic valida l'input automaticamente
# Async significa che possiamo gestire altre richieste mentre questa è in corso
return await compute_embeddings(request.texts)
Perché non Flask? Solo sincrono, più lento per richieste concorrenti.
Perché non Django? Pesante, troppe funzionalità per una semplice API.
I Tre Endpoint Core
Il tuo servizio FastAPI espone tre endpoint (chiamati dai workflow n8n):
1. POST `/embed` - Genera Embeddings Vettoriali
Scopo: Converti testo in vettori di 768 dimensioni
Input:
{
"texts": ["Qual è la politica di ferie?", "Capitolo 3 manuale HR"],
"model": "sentence-transformers/all-MiniLM-L6-v2",
"normalize": true
}
Output:
{
"embeddings": [
[-0.042, 0.156, -0.089, ..., 0.651], // primo testo
[0.103, -0.051, 0.248, ..., -0.172] // secondo testo
],
"model": "all-MiniLM-L6-v2",
"model_dim": 768,
"inference_time_ms": 45
}
Parametri chiave:
texts: Array di stringhe da incorporare (batch processing per efficienza)model: Quale modello di embedding usare (configurabile)normalize: Normalizzazione L2 opzionale (per ottimizzazione della similarità coseno)
Nota di performance: Batch di 10 testi insieme è ~5x più veloce che 10 richieste separate.
2. POST `/rerank` - Migliora la Rilevanza dei Risultati di Ricerca
Scopo: Re-scorifica i risultati recuperati in base alla rilevanza della query
Perché? La similarità vettoriale è buona ma non perfetta. Un reranker usa modelli cross-encoder per scorificare le coppie query-documento più accuratamente.
Input:
{
"query": "Quanti giorni di ferie ho?",
"documents": [
"Ottieni 20 giorni di ferie per anno",
"Puoi richiedere tempo libero qui",
"La politica di parcheggio è nella sezione 5"
],
"top_k": 2,
"model": "cross-encoder/ms-marco-MiniLM-L-6-v2"
}
Output:
{
"ranked": [
{"doc": "Ottieni 20 giorni di ferie per anno", "score": 0.94},
{"doc": "Puoi richiedere tempo libero qui", "score": 0.72}
],
"model": "cross-encoder/ms-marco-MiniLM-L-6-v2",
"inference_time_ms": 120
}
Quando usare il reranking:
- I risultati top_k di Qdrant sono vicini in similarità (need better discrimination)
- La query è complessa o ambigua
- Puoi permetterti 50-200ms di latenza extra per accuratezza migliore
Quando saltare: Query semplici, percorsi critici per performance (es. chat real-time con SLA < 100ms).
3. GET `/config` - Interroga la Configurazione del Servizio
Scopo: Comunica quali modelli sono disponibili e lo stato del servizio
Output:
{
"service": "RAG NLP Engine",
"embedding_models": [
{
"name": "all-MiniLM-L6-v2",
"dimensions": 384,
"inference_time_ms": 25,
"languages": ["en", "multilingual"]
},
{
"name": "all-mpnet-base-v2",
"dimensions": 768,
"inference_time_ms": 45,
"languages": ["en", "multilingual"]
},
{
"name": "multilingual-e5-large",
"dimensions": 1024,
"inference_time_ms": 80,
"languages": 100+
}
],
"reranker_models": [
{
"name": "cross-encoder/ms-marco-MiniLM-L-6-v2",
"inference_time_ms": 120
}
],
"gpu_available": true,
"gpu_model": "NVIDIA A40",
"memory_usage_mb": 2048,
"status": "healthy"
}
Perché esporre config? Il backend NestJS interroga questo all'avvio per visualizzare i modelli disponibili nell'admin UI. Gli utenti possono scegliere quale modello usare per query.

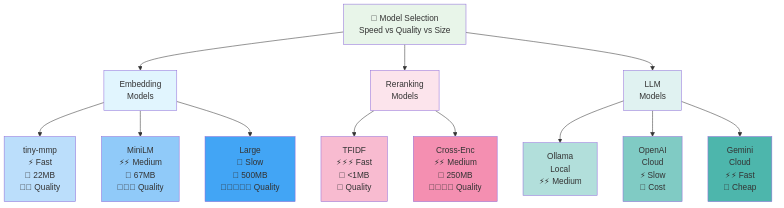
Selezione del Modello: Trade-off e Strategia
Non tutti i modelli di embedding sono uguali. Differiscono in velocità, qualità e supporto linguistico:
Leggero vs Alta Qualità:
Veloce & Piccolo:
- all-MiniLM-L6-v2 (384 dims, 25ms, 22MB)
- Buono per: QPS alto, deployment cost-sensitive
Medio:
- all-mpnet-base-v2 (768 dims, 45ms, 430MB)
- Buono per: Accuratezza bilanciata/velocità
Alta Qualità:
- multilingual-e5-large (1024 dims, 80ms, 2GB)
- Buono per: Massima accuratezza, supporto multilingue
Considerazioni linguistiche:
Ottimizzato per Inglese:
- Più veloce, più piccolo, miglior accuratezza su Inglese
- all-MiniLM-L6-v2, all-mpnet-base-v2
Multilingue:
- Supporta 50+ lingue in un modello
- multilingual-e5-large, xlm-roberta-base
- Trade-off: Più grande, più lento, ma un modello per tutte le lingue
Il tuo approccio pragmatico: Inizia con all-MiniLM-L6-v2 (veloce, abbastanza buono). Se l'accuratezza diventa un problema, upgrade a all-mpnet-base-v2. Se i tuoi documenti sono multilingue, salta a multilingual-e5-large.
Insight chiave: La selezione del modello è configurazione, non codice:
{
"embeddings": {
"default_model": "all-MiniLM-L6-v2",
"reranker_model": "cross-encoder/ms-marco-MiniLM-L-6-v2",
"batch_size": 32,
"use_gpu": true
}
}
Cambia il JSON, riavvia il servizio. Nessun cambio di codice.
GPU vs CPU: La Realtà della Performance
Percorso CPU:
- Inferenza su Intel Xeon: ~80-200ms per query
Percorso GPU:
- NVIDIA A40: ~15-30ms per query
- NVIDIA T4: ~30-50ms per query
- NVIDIA A100: ~5-10ms per query
Moltiplicatore vantaggio GPU: 5-15x più veloce
Ma le GPU costano soldi. Quando ha senso?
GPU vale la pena quando:
- QPS > 100 (fai query costantemente)
- Latenza SLA < 100ms (hai bisogno di velocità)
- Costo GPU è compensato da meno core CPU (o costo cloud)
CPU va bene quando:
- QPS < 50 (le query sono intermittenti, non costanti)
- Latenza SLA > 200ms (gli utenti possono aspettare)
- Nessun budget GPU
Il tuo setup: Se hai una GPU disponibile, FastAPI auto-rileva e la usa. Altrimenti, fallback a CPU. Guidato da configurazione.
# FastAPI startup
if torch.cuda.is_available():
device = "cuda"
else:
device = "cpu"
model = SentenceTransformer("all-MiniLM-L6-v2").to(device)
Pattern di Ottimizzazione: Renderlo Veloce
Batching
Tecnica: Raggruppa più richieste di embedding
Senza batching:
Richiesta 1: testo → embed → 45ms
Richiesta 2: testo → embed → 45ms
Richiesta 3: testo → embed → 45ms
Totale: 135ms
Con batching:
Batch [testo1, testo2, testo3] → embed → 50ms (moltiplicazione matriciale è parallelizzata)
Totale: 50ms
Speedup: 2.7x
Capacità di n8n: Esegui ciclo attraverso documenti, accumula 32 per volta, invia batch a FastAPI.
Model Caching
Senza caching:
Richiesta 1: Carica modello (2GB, 500ms) + embed → 545ms
Richiesta 2: Carica modello + embed → 545ms
Richiesta 3: Carica modello + embed → 545ms
Con caching:
Richiesta 1: Carica modello (500ms) + embed → 545ms
Richiesta 2: Usa modello cache + embed → 45ms
Richiesta 3: Usa modello cache + embed → 45ms
FastAPI carica modelli all'avvio, li mantiene in memoria. Le richieste successive riutilizzano i modelli caricati.
Async Request Handling
Senza async (Flask):
Richiesta 1 arriva → Processa (100ms) → Risposta
Richiesta 2 arriva → Aspetta Richiesta 1 → Processa (100ms) → Risposta
Totale per 2 richieste: 200ms
Con async (FastAPI):
Richiesta 1 arriva → Inizia elaborazione (non-bloccante)
Richiesta 2 arriva → Inizia elaborazione (non-bloccante)
Entrambe completano in ~100ms (parallelizzate)
Totale per 2 richieste: ~110ms
Speedup: 1.8x
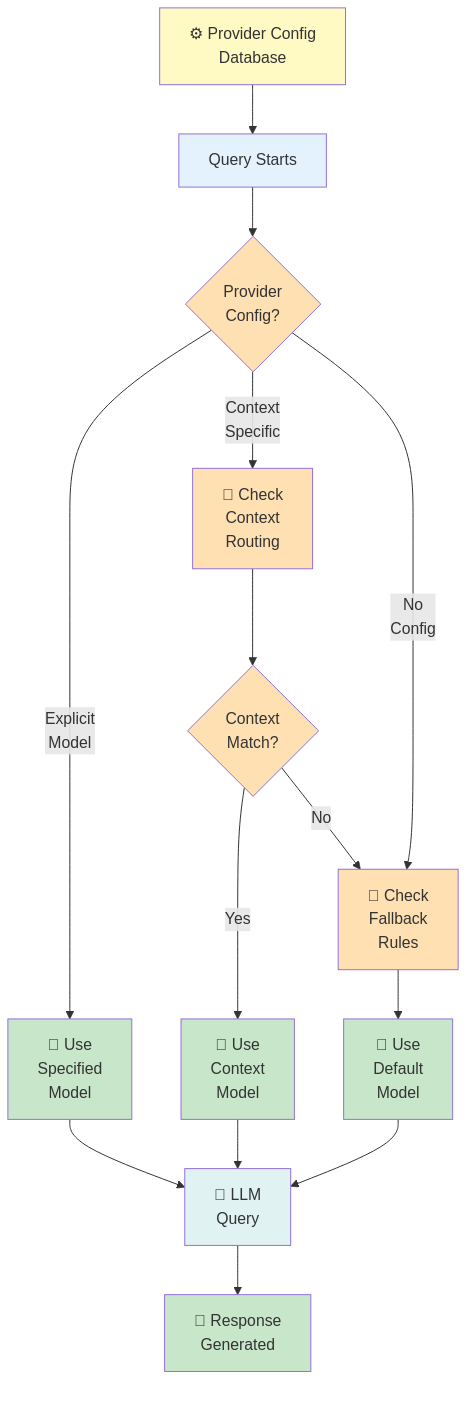
Selezione del Modello Guidata da Configurazione
Il tuo sistema RAG non fa hardcode delle scelte di modello. Invece, il backend (NestJS) memorizza la configurazione del modello per contesto:
Contesto: "policy_documents"
├─ embedding_model: "all-mpnet-base-v2"
├─ reranker_model: "cross-encoder/qnli"
└─ top_k: 10
Contesto: "technical_docs"
├─ embedding_model: "multilingual-e5-large"
├─ reranker_model: null (salta reranking per velocità)
└─ top_k: 5
n8n legge questa configurazione e chiama gli endpoint appropriati:
Workflow n8n:
1. Ottieni configurazione contesto da NestJS
2. Chiama FastAPI /embed con config.embedding_model
3. Cerca in Qdrant
4. Se config.reranker_model: Chiama FastAPI /rerank
5. Continua...
Risultato: Contesti diversi usano strategie diverse, tutto orchestrato da n8n, tutto configurabile in NestJS.
Integrazione con n8n: Il Contratto
n8n non sa (o non importa) di PyTorch, transformers, o CUDA. Sa solo:
POST http://fastapi:8000/embed
Content-Type: application/json
{
"texts": [...lista di stringhe...],
"model": "all-MiniLM-L6-v2",
"normalize": true
}
→ 200 OK
{
"embeddings": [...lista di vettori...],
"inference_time_ms": 45
}
Questo è il contratto. Finché FastAPI lo rispetta, n8n non importa che cosa c'è dentro.
Perché importa: Potresti sostituire FastAPI con un servizio Go/Rust domani, cambiare l'URL endpoint in n8n, e tutto funziona. Stessa orchestrazione, backend diverso.
Conclusione: Servizi Specializzati, Orchestrati Pulitamente
Il ruolo di FastAPI nel tuo sistema RAG è focalizzato: genera embeddings, riordina i risultati, espone la configurazione. Non prova a essere "l'API" per tutto (è NestJS). Non prova a essere "l'orchestratore" (è n8n). Fa una cosa bene.
Questa specializzazione è quello che rende i sistemi RAG mantenibili:
- NestJS gestisce la logica di business, autenticazione, permessi
- FastAPI gestisce task NLP computazionalmente intensivi
- n8n li orchestra
- Qdrant memorizza i vettori
- PostgreSQL memorizza i metadati
Ogni strumento ha una responsabilità chiara. Sostituisci implementazioni senza rompere il sistema.
---
GitHub:
- RAD System (open-source): https://github.com/msbragi/rad-system
- RAG System (technology overview & examples — source not published): https://github.com/msbragi/RAG-System-Dist
Costruito con: FastAPI (microservizio), sentence-transformers (embeddings), PyTorch (inferenza), asyncio (concorrenza), Pydantic (validazione).