")
")
Come i Computer Enumerano il Significato Semantico
Perché la Ricerca Semantica Supera il Matching per Parole Chiave (E Perché i Metadati Contano)
La ricerca è inefficace. Provate a cercare nei documenti aziendali con parole chiave: "giorni di ferie" restituisce risultati su giorni di malattia, piani pensionistici e politiche di viaggio—tutto tranne la politica sulle ferie. È un caos.
Questa è la limitazione della ricerca basata su parole chiave. Cerca corrispondenze esatte, non significati. Entra in gioco la ricerca semantica: capire cosa significa un testo, non solo quali parole contiene. E la tecnologia dietro la ricerca semantica? Gli embeddings vettoriali.
Questo articolo esplora cosa sono gli embeddings, perché Qdrant è diventato il mio database vettoriale preferito e, soprattutto: le decisioni architetturali che rendono i sistemi RAG resilienti e intercambiabili.
Dalle Parole Chiave alla Semantica: Perché È Importante
Immaginate che il vostro sistema RAG abbia indicizzato 10.000 documenti interni sulle politiche HR. Un utente chiede: "Quanti giorni di ferie ho?"
Approccio con ricerca per parole chiave:
CERCA documenti DOVE il contenuto CONTIENE "giorni" E "ferie"
→ Risultati: giorni di ferie, giorni di malattia, congedo di maternità, moduli di richiesta ferie...
→ Utente: "Non è quello che ho chiesto!"
Approccio con ricerca semantica:
1. Converti la domanda in una rappresentazione semantica
2. Trova documenti con significato semantico simile
3. Restituisci: "Politica sulle Ferie" (corrispondenza esatta nel significato)
4. Utente: "Perfetto!"
La differenza? Comprensione. La ricerca semantica sa che "quanti giorni di ferie" corrisponde semanticamente a "diritto alle ferie" anche se le parole esatte differiscono.
Cosa Sono gli Embeddings? (Versione per Sviluppatori)
Saltate il manuale sulle reti neurali. Ecco cosa dovete sapere:
Embedding = Testo Convertito in Numeri
Input: "Qual è la politica sulle ferie?"
↓
[Il modello ML elabora il testo]
↓
Output: [-0.042, 0.156, -0.089, 0.203, ..., 0.651]
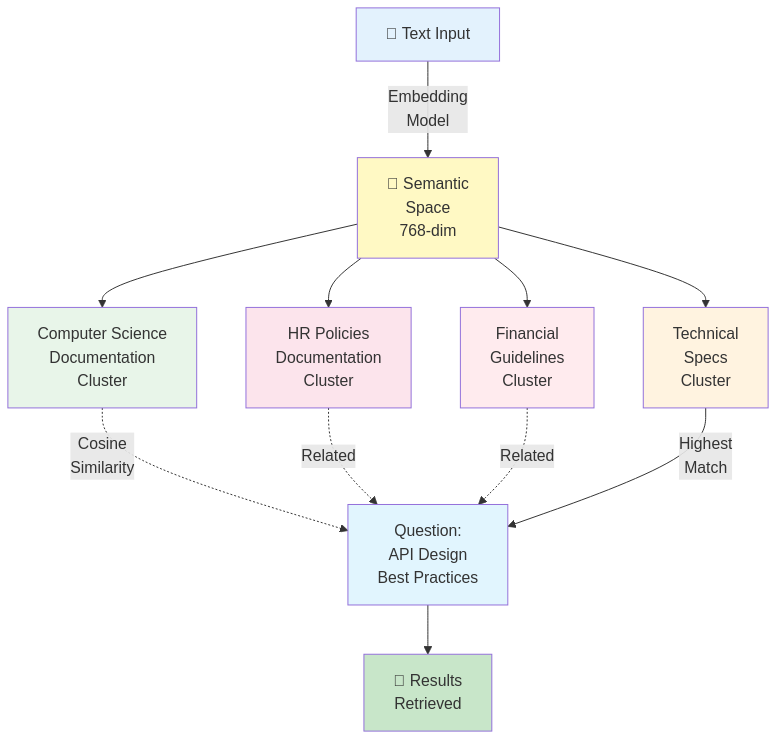
Intuizione chiave: I significati simili si raggruppano nello spazio.
Spazio Semantico (visualizzazione):
Perché funziona:
- Il modello ML ha appreso schemi da miliardi di testi
- Capisce che "giorni di ferie" e "tempo libero" significano cose simili
- Quando cerchi, trova i vicini semantici più prossimi
Spiegazione senza matematica: Se le parole chiave sono coordinate GPS, gli embeddings sono un sistema GPS che comprende il contesto. Stessa destinazione, ma sa quali strade hanno senso.
Perché Qdrant?
Quando scegliete un database vettoriale, avete opzioni:
| Database | Pro | Contro |
|---|---|---|
| Qdrant | Veloce, user-friendly, API REST pulita, scalabilità orizzontale, nessun sovraccarico di schema | Richiede un archivio di metadati separato (in realtà un vantaggio, vedi sotto) |
| ChromaDB | Semplice inferenza di embedding integrata | Scala limitata, ricerca di similarità più lenta |
| Weaviate | Linguaggio di query ricco, modelli di metadati integrati | Complessità operativa, curva di apprendimento più ripida |
| Pinecone | Gestito (nessuna infrastruttura), completamente serverless | Vincolo al fornitore, prezzi per vettore |
| pgvector (PostgreSQL) | Nessun nuovo strumento, tutto in Postgres | Più lento per la ricerca di similarità su larga scala, non ottimizzato per i vettori |
La mia scelta: Qdrant
Perché?
- Velocità: Algoritmo HNSW (ricerca dei vicini più prossimi super veloce, anche con milioni di vettori)
- Semplicità: API REST pulita, gestione delle collezioni semplice
- Scalabilità: Può funzionare in modalità nodo singolo o cluster
- Flessibilità: Può sostituire componenti senza grandi rischi (vedi "astrazione n8n" sotto)
- Nessun vincolo al fornitore: Open-source, opzione self-hosted
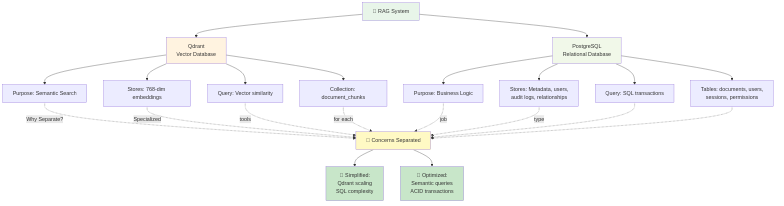
Decisione Architetturale: Separare le Responsabilità
Ecco dove la maggior parte delle persone si confonde. Qdrant può memorizzare metadati accanto ai vettori (usando i payload). "Perché non memorizzare tutto in Qdrant?"
Perché la separazione delle responsabilità supera la comodità.
Il Caso per la Separazione
Qdrant memorizza: Vettori + Riferimenti Leggeri
{
"id": "chunk_12345",
"vector": [-0.042, 0.156, ..., 0.651],
"payload": {"document_id": 789, "chunk_index": 2, "context_key": "policy_docs"}
}
PostgreSQL memorizza: Tutto il Resto
CREATE TABLE documents (
id SERIAL PRIMARY KEY,
title TEXT,
content TEXT
);
Perché Questa Separazione?
1. Prestazioni
- La ricerca vettoriale è ottimizzata per la similarità (HNSW). Veloce.
- Le query relazionali (JOIN, transazioni) sono ottimizzate in SQL. Veloce.
- Mischiare entrambi in un unico sistema? Nessuno dei due è ottimale.
2. Conformità e Audit
- I requisiti normativi spesso richiedono integrità relazionale
- Soft-delete, audit trail, RBAC—questi vivono in SQL
- I payload di Qdrant non sono transazionali
3. Sostituibilità
- Se domani sostituite Qdrant con Weaviate, PostgreSQL non cambia
- Se aggiungete un secondo database vettoriale per A/B testing, lo stesso archivio di metadati serve entrambi
- Questa è architettura agnostica in azione
4. Consistenza dei Dati
- Le transazioni atomiche in PostgreSQL garantiscono la consistenza
- Eliminazione di documenti: aggiornate i metadati in Postgres, i webhook attivano n8n per eliminare i vettori
- Nessun vettore orfano, nessun metadato orfano
Concetti di Qdrant: Cosa Dovete Sapere
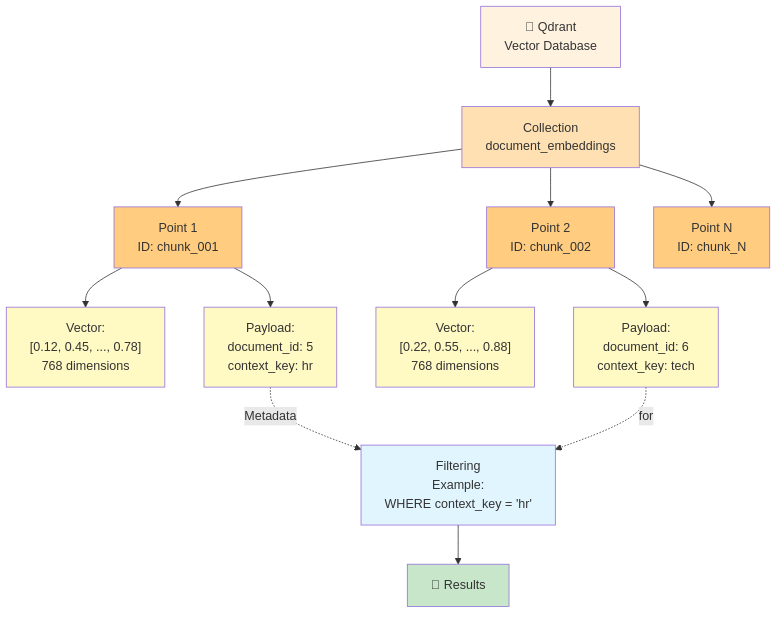
Collezione = Namespace per i vettori
Collezione: "policy_documents"
Punti = Vettori individuali con ID
ID Punto: chunk_12345
Vettore: [-0.042, 0.156, ..., 0.651] (768 dimensioni)
Payload: {document_id: 789, chunk_index: 2, context_key: "policy_docs"}
Payload = Metadati leggeri associati ai punti
Payload (mantenere minimo):
{
"document_id": 789,
"chunk_index": 2
}
Filtraggio = Restringere i risultati della ricerca tramite payload
Query di ricerca:
- Trova vettori simili a: [embedding di "ferie"]
- Limita a: context_key == "policy_docs"
- Restituisci: primi 5 risultati
Ricerca in Pratica: Il Flusso
L'utente chiede: "Quali benefici per le ferie ho?"
1. Embed Query:
Input: "Quali benefici per le ferie ho?"
Modello: all-mpnet-base-v2
Output: [0.123, -0.456, 0.789, ...] (768 dim)
2. Ricerca Vettoriale Qdrant:
Input: Vettore query (768 dim)
Algoritmo: HNSW
Output: Top 5 vettori + punteggi di distanza
Costruito con: Qdrant (ricerca vettoriale), PostgreSQL (metadati), n8n (livello di astrazione), FastAPI (embeddings), NestJS (logica di business).