")
")
Architettura RAG: Dal Concetto alla Produzione
Architettura RAG: Dal Concetto alla Produzione
Nell'era dell'AI, le organizzazioni sono sommerse nella documentazione. Manuali di policy, materiali di formazione, wiki interni, specifiche tecniche — l'informazione esiste, ma trovare la risposta giusta al momento giusto rimane una sfida. Questa è la storia di come ho costruito un sistema Retrieval-Augmented Generation (RAG) pronto per la produzione, progettato per risolvere questo problema mantenendo un vincolo critico: la sovranità dei dati.
Cos'è RAG?
Retrieval-Augmented Generation è una tecnica che migliora i Modelli Linguistici di Grandi Dimensioni (LLM) radicando le loro risposte nei vostri documenti. Piuttosto che fare affidamento solo sulla conoscenza pre-addestrata del modello, i sistemi RAG:
- Recuperano informazioni rilevanti da una base di conoscenza curata
- Aumentano il prompt dell'LLM con questo contesto
- Generano risposte accurate con citazioni
Pensatelo come dare a un assistente AI una memoria fotografica della documentazione della vostra organizzazione, con la capacità di citare esattamente da dove proviene ogni fatto.
Il Problema che RAG Risolve:
- Gli LLM hanno conoscenze obsolete o generiche
- L'ottimizzazione fine è costosa e impraticabile per contenuti frequentemente aggiornati
- Le allucinazioni possono essere pericolose in contesti enterprise
- Nessuna attribuzione della fonte significa nessuna fiducia
La Soluzione RAG:
- Conoscenza fresca e specifica dell'organizzazione
- Aggiornamenti semplici dei documenti (nessun nuovo addestramento necessario)
- Risposte fondate con citazioni
- Risposte spiegabili e auditable
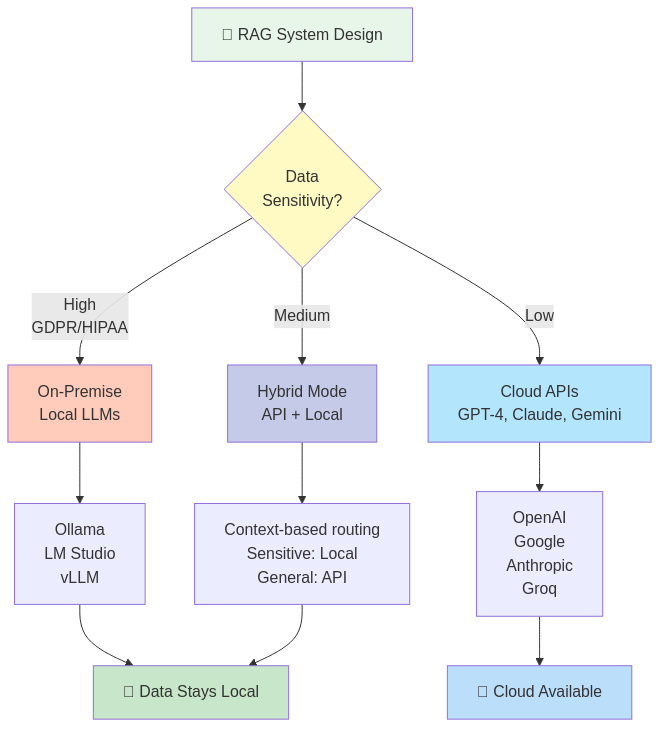
La Sfida della Privacy: Perché l'Architettura Agnostica Importa
Durante la fase di progettazione, ho affrontato una decisione critica: API LLM basate su cloud o inferenza on-premise? La risposta è stata entrambe — e quella scelta ha plasmato l'intera architettura.
La Realtà Enterprise
Diverse organizzazioni hanno diversi vincoli:
Requisiti On-Premise:
- Provider sanitari vincolati da HIPAA
- Istituzioni finanziarie con conformità PCI-DSS
- Agenzie governative con dati classificati
- Aziende europee sotto interpretazione rigorosa di GDPR
Vantaggi delle API Cloud:
- Startup che necessitano di deployment rapido
- Team senza esperienza in infrastrutture ML
- Progetti con workload variabile (pay-per-use)
- Accesso ai modelli più avanzati (GPT-4, Claude, Gemini)
La Soluzione Agnostica
Piuttosto che forzare una scelta, il sistema supporta il cambio senza interruzioni tra:
- API Cloud: OpenAI, Google Gemini, Anthropic Claude, Groq
- Engine Locali: Ollama, LM Studio, vLLM, llama.cpp
- Modalità Ibrida: Dati sensibili elaborati localmente, query generiche via API
Nessun cambio di codice richiesto — solo aggiornamenti di configurazione. Questo significa:
- Iniziare con API cloud per prototipazione rapida
- Transizione a on-premise mentre i bisogni di conformità crescono
- Eseguire entrambi contemporaneamente per contesti diversi
- Valutare nuovi modelli senza riscritture architettoniche
Panoramica dell'Architettura: Microservizi Per Design
Il sistema è costruito come un'architettura distribuita di microservizi, dove ogni componente ha una responsabilità singola e ben definita. Questo approccio abilita:
- Scaling indipendente di servizi computazionalmente intensivi (embeddings, inference)
- Ottimizzazione tecnologia-specifica (Python per NLP, TypeScript per logica di business)
- Separazione chiara delle responsabilità
- Debug e monitoraggio semplificati
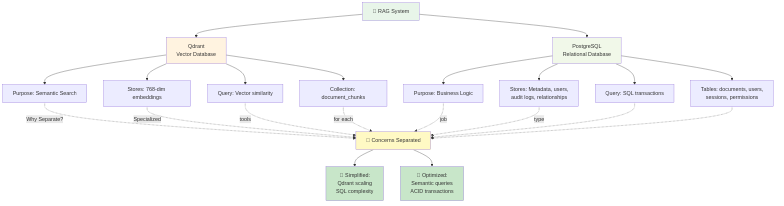
Analisi dei Componenti
**Qdrant - Motore di Ricerca Vettoriale**
Scopo: Memorizza gli embeddings dei documenti per la ricerca semantica
Perché Qdrant:
- Ricerca di similarità vettoriale nativa (algoritmo HNSW)
- Capacità di filtraggio dei metadati
- Scalabilità orizzontale
- Sviluppo attivo e comunità forte
Decisione Chiave: I metadati vivono in PostgreSQL, non in Qdrant. Mentre Qdrant supporta l'archiviazione dei payload, separare le responsabilità significa:
- Query di business complesse rimangono in SQL relazionale
- La ricerca vettoriale si concentra sulla similarità semantica
- Nessuna duplicazione dei dati di audit/conformità
**n8n - Orchestratore di Workflow**
Scopo: Workflow visivi per l'ingestion di documenti e pipeline di query
Perché n8n:
- Design di workflow low-code (debug visivi)
- Gestisce operazioni asincrone (parsing PDF, generazione embeddings)
- Gestione degli errori e logica di retry built-in
- Trasformazione/normalizzazione dei dati tra servizi
Workflow Principali:
- Upload PDF → Parse → Chunk → Embed → Store
- Query Utente → Embed → Search → Retrieve → LLM → Answer
- Cancellazione Documento → Pulizia vettori + metadati
- Re-indexing programmato e health checks
**FastAPI - Engine NLP Python**
Scopo: Generazione di embeddings e reranking
Perché FastAPI:
- Ecosistema Python per NLP (sentence-transformers, Hugging Face)
- Performance asincrona veloce
- Auto-generazione della documentazione OpenAPI
- Cambio facile dei modelli via configurazione
Endpoints:
/embed- Genera embeddings vettoriali per il testo/rerank- Affina i risultati di ricerca per rilevanza/config- Query modelli disponibili e configurazione
**PostgreSQL - Metadati & Logica di Business**
Scopo: Dati relazionali, sessioni, tracce di audit
Memorizza:
- Account utenti e permessi (RBAC)
- Metadati dei documenti (titolo, source_url, upload_date, proprietario)
- Sessioni chat e storico conversazioni
- Contesti (domini di conoscenza come "HR Policies", "Tech Docs")
- Testo chunk e riferimenti (collegati a ID vettoriali)
Perché separato dal Database Vettoriale: SQL eccelle in join, transazioni e query complesse. Gli audit di conformità richiedono integrità relazionale.
**NestJS Backend - Livello API Sicuro**
Scopo: Logica di business, autenticazione, gestione documenti
Costruito sul framework RAD-System (leggi di più), questo servizio fornisce:
- Autenticazione basata su JWT con token di refresh
- Controllo accesso basato su ruoli (User, Admin, SuperUser)
- API RESTful per tutte le operazioni CRUD
- Integrazione con workflow n8n
- Documentazione Swagger su
/api-docs/v1
Vantaggi del Framework:
- Servizi base generici (principio DRY)
- Soft-delete e colonne di audit built-in
- Helper SQL agnostici dal database (PostgreSQL, MySQL, SQLite)
- Interceptor e guard security-first
**Angular Frontend - Interfaccia Chat Moderna**
Scopo: UI chat rivolto all'utente e funzioni admin
- Componenti standalone (nessun NgModules)
- Material Design 3 (mat-components)
- Transloco per i18n (supporto multilingua)
- Chat in tempo reale con risposte in streaming
- Dashboard admin per gestione documenti/contesti
- Rendering UI basato su ruoli
**Redis - Livello di Caching**
Scopo: Ottimizzazione delle prestazioni
- Archiviazione sessioni (caching validazione JWT)
- Configurazione frequentemente acceduta
- Rate limiting per endpoint API
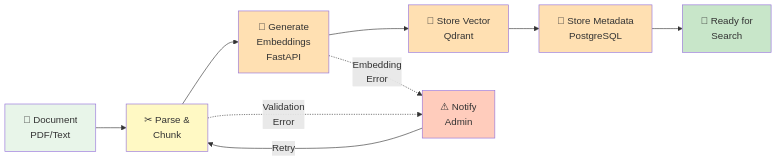
Flusso dei Documenti: Dall'Upload alla Conoscenza Ricercabile
Ecco come un PDF diventa una conoscenza interrogabile:
[Utente Carica PDF]
↓
[Backend: Memorizza file, crea record metadati]
↓
[Attiva workflow n8n]
↓
[n8n: Recupera PDF da storage]
↓
[n8n: Estrae testo (Unstructured.io / PyPDF)]
↓
[n8n: Divide in chunk (500-1000 token)]
↓
[n8n: Chiama FastAPI /embed per ogni chunk]
↓
[FastAPI: Genera embeddings vettoriali]
↓
[n8n: Memorizza vettori in Qdrant con riferimento document_id]
↓
[n8n: Memorizza testo chunk in PostgreSQL con vector_id]
↓
[n8n: Aggiorna stato documento a "indexed"]
↓
[Utente notificato: Documento pronto per query]
Dettagli Chiave:
- Chunk sovrapposti di 100 token (continuità contesto)
- Ogni chunk contiene metadati:
{document_id, page_number, context_key} - Sicurezza transazionale: rollback in caso di fallimento (no indici parziali)
Flusso delle Query: Dalla Domanda alla Risposta Citata
Quando un utente pone una domanda:
[Utente: "Qual è la politica di ferie?"]
↓
[Frontend: Invia a NestJS /chat/query]
↓
[NestJS: Valida permessi utente + accesso contesto]
↓
[NestJS: Attiva workflow RAG n8n]
↓
[n8n: Chiama FastAPI /embed con domanda]
↓
[FastAPI: Converte domanda in vettore]
↓
[n8n: Cerca Qdrant (top_k=5, filtrato per contesto)]
↓
[Qdrant: Restituisce 5 chunk ID più simili + punteggi similarità]
↓
[n8n: Recupera testo chunk da PostgreSQL]
↓
[n8n: Reranking opzionale via FastAPI]
↓
[n8n: Costruisce prompt LLM con contesto recuperato]
↓
[n8n: Instrada a LLM configurato (Gemini/OpenAI/Ollama)]
↓
[LLM: Genera risposta con citazioni [REF-1], [REF-2]]
↓
[n8n: Mappa citazioni a documenti sorgente]
↓
[NestJS: Salva messaggio chat in storico]
↓
[Frontend: Mostra risposta con link sorgente cliccabili]
Ottimizzazioni delle Prestazioni:
- Generazione embeddings: ~50ms (locale) a 200ms (API)
- Ricerca vettoriale: <100ms per 100K documenti
- Reranking (opzionale): Scambia velocità per precisione
- Streaming risposte: Utente vede risposte parziali in modo incrementale

Prossimi Passi: Serie di Articoli di Approfondimento
Questa panoramica gratta solo la superficie. Nei prossimi articoli, esploreremo ogni componente in profondità:
- n8n Orchestration: Workflow Visivi per Pipeline AI - Approfondimento nei workflow di ingestion/query, gestione errori e pattern asincroni
- Qdrant & Embeddings Vettoriali Spiegati - Come funziona la ricerca semantica, scegliere modelli di embedding e sintonizzare la rilevanza
- Engine NLP FastAPI: Embeddings & Reranking - Costruire il servizio Python, selezione modelli e ottimizzazione prestazioni
- Backend Sicuro NestJS con Framework RAD-System - Autenticazione, RBAC, servizi generici e design API
- Interfaccia Chat Angular RAG - Costruire il frontend, risposte in streaming e funzioni admin
- Cambio Provider LLM: Libertà di Scelta - Strategie di configurazione, prompt engineering e ottimizzazione costi
- Deployment & DevOps: Docker, Monitoraggio e Scaling - Produzione pronta, osservabilità e infrastruttura
Interessato al progetto? Il Sistema RAG è un prodotto commerciale — il codice sorgente non è pubblicato. Su GitHub condivido la panoramica tecnologica e esempi documentati per chi vuole comprendere l'architettura prima di contattarmi.
---
Conclusione
Costruire un sistema RAG non è solo collegare un LLM a un database vettoriale — è prendere decisioni architettoniche che rispettano la privacy, abilitano la flessibilità e scalano con i bisogni organizzativi. Progettando per agnosticismo (cloud vs on-premise), modularità (microservizi) e esperienza dello sviluppatore (workflow visivi, API auto-generate), il sistema si adatta a esigenze diverse senza sacrificare sicurezza o prestazioni.
Il percorso dal concetto alla produzione mi ha insegnato che nessun singolo componente importa in isolamento — è l'integrazione consapevole, il rispetto della sovranità dei dati e la comprensione che le aziende hanno bisogno di opzioni, non prescrizioni, che rende un sistema RAG veramente pronto per l'enterprise.
Restate sintonizzati per gli approfondimenti. Sto giusto iniziando.
---