")
")
Workflow Visivi per Pipeline AI
Da Manuale a Automatico: Orchestrare Sistemi RAG Complessi
Immaginate di dover coordinare 10 servizi distribuiti, ciascuno parlando un linguaggio diverso (Python, TypeScript, OpenAI API, Qdrant), gestendo timeouts, retry e fallimenti — il tutto mentre gli utenti caricano documenti e pongono domande in tempo reale.
Questo è dove n8n brilla. È un framework di orchestrazione di workflow visivo che trasforma le pipeline complesse in diagrammi trascinabili, eliminando la maggior parte dei boilerplate e consentendo al team di debuggare visivamente piuttosto che frugare nei log.
Perché n8n Nel Sistema RAG
In un primo momento, ho considerato di scrivere orchestratore diretta in Python o Node.js. Ma c'è un costo nascosto: ogni componente aggiunto crea un incrocio di complessità.
- Cosa succede se FastAPI è giù? Che timeout impostare?
- Se un documento fallisce durante l'ingestion al passaggio 3 di 7, come ritrattare?
- Un nuovo membro del team deve comprendere il codice prima di potere capire il flusso
- Quando il business vuole "aggiungere solo un pre-processing step", si ritrova un deploy di codice
n8n Risolve Questo:
- Workflow visivi = documentazione eseguibile
- Gestione errori built-in: retry, fallback, webhook
- Nessun deploy per modifiche ai workflow
- Integrazione nativa con 400+ servizi (API REST, database, file store)
- Debug passo a passo con ispezione dei dati intermedi
Architettura n8n Nel Sistema RAG
n8n non è un rimpiazzo per l'API backend. È il orchestratore degli operatori specializzati:
User Request (via NestJS)
↓
[Backend NestJS: Valida, autorizza]
↓
[Chiama n8n webhook]
↓
[n8n: Orchiestra workflow]
↓
[Workflow n8n: Chiama FastAPI, Qdrant, LLM, ecc.]
↓
[Workflow n8n: Aggrega risultati, maneggia errori]
↓
[Restituisce risultato a NestJS]
↓
[Backend: Salva in PostgreSQL]
↓
[Frontend: Mostra all'utente]
È importante notare: n8n non rimpiazza l'API backend. È il middleware di orchestrazione — il backend rimane responsabile dell'autenticazione, dello storage, e della logica di business. n8n si occupa di operazioni computazionalmente intensive e asincrone.
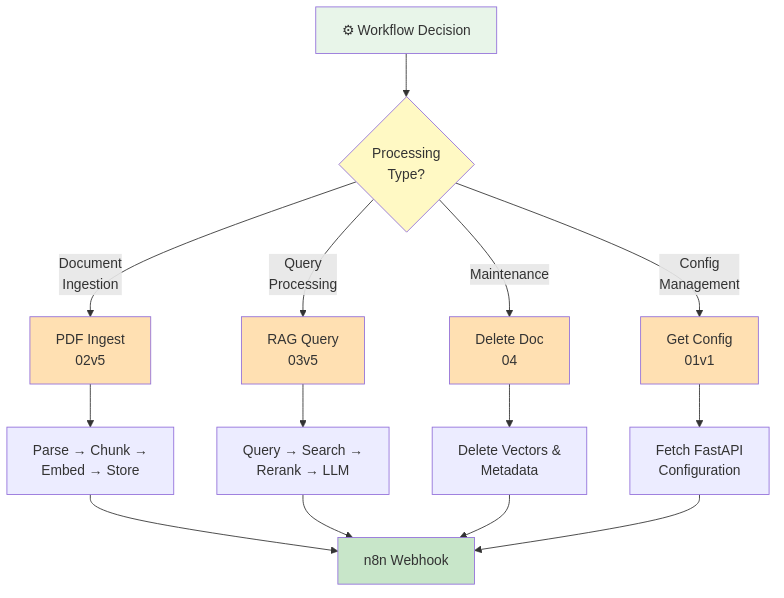
Workflow RAG Principali
**Workflow 1: Document Ingestion Pipeline**
Quando un utente carica un PDF, il backend attiva questo workflow:
Input: {document_id, file_path, context_id, user_id}
1. [File Storage Node]
- Recupera PDF dalla storage
- Valida formato e dimensione
2. [PDF Extract Node]
- Usa Unstructured.io (tramite API HTTP o locale)
- Estrae testo grezzo, layout, immagini
- Fallback: PyPDF se Unstructured fallisce
3. [Text Normalizer Node]
- Pulisce spazi bianchi
- Normalizza encoding (UTF-8)
- Rimuove header/footer ripetitivi
- Opzionale: Verifica OCR (se PDF scansionato)
4. [Chunking Node]
- Divide in chunk di 500-1000 token
- Sovrappone di 100 token (continuità contesto)
- Crea metadati per ogni chunk: {page, section, context}
5. [Embedding Loop]
- Per ogni chunk:
a. Chiama FastAPI /embed
b. Riceve vettore 384-dim (o più)
c. Batch embed se batch_size > 1
- Retry 3x su timeout
6. [Qdrant Store]
- Inserisce vettore in Qdrant con ID univoco
- Allega metadati: {document_id, page, chunk_index}
7. [PostgreSQL Store]
- Memorizza testo chunk, vector_id, document_id
- Crea record di audit
8. [Update Status]
- Cambia stato documento a "indexed"
- Calendario di notification utente
9. [Error Handling]
- Se fallibilità ad un passaggio, rollback
- Memorizza logs di errore
- Invia notifica admin
- Consente retry manuale
Output: {success: true, chunks_processed: N, vectors_stored: N}
Timeout e Retry:
- File download: 30s timeout, 3 retry
- Embedding API: 60s timeout, 5 retry (batch piccoli su fallimento)
- Qdrant store: 10s timeout, 3 retry (idempotente via ID)
**Workflow 2: Query & RAG Answering**
Quando un utente pone una domanda:
Input: {user_id, context_id, query_text, session_id}
1. [Validate Query]
- Lunghezza query: 10-2000 caratteri
- Verifica permessi RBAC (utente può accedere contesto?)
- Controlla rate limiting
2. [Embed Query]
- Chiama FastAPI /embed con query
- Riceve vettore query
3. [Qdrant Search]
- Ricerca similarità: top_k=10, threshold=0.7
- Filtra per context_id
- Restituisce chunk IDs e score similarità
4. [Fetch Chunk Data]
- Batch query PostgreSQL
- Recupera testo, page_number, source_url per ogni chunk
5. [Reranking (Opzionale)]
- Se rerank_enabled: Chiama FastAPI /rerank
- Passa query + chunk text
- Riceve reranked liste (ridotto a top_k=3)
6. [Prompt Composition]
- Struttura prompt per LLM:
a. System instruction (ruolo, tone, guidelines)
b. Context: "Informazioni rilevanti:" + primo chunk, secondo, terzo
c. Query utente
d. Instruction: "Cita le tue fonti usando [REF-1], [REF-2]"
7. [LLM Query]
- Chiama provider configurato (OpenAI/Gemini/Ollama)
- Streaming risposta o batch a seconda configurazione
- Timeout: 120s
8. [Parse Citations]
- Estrae [REF-1], [REF-2] dalla risposta
- Mappa a documento sorgente, page number, URL
9. [Store Chat Message]
- Salva messaggio utente
- Salva risposta model con metadati citazione
10. [Stream to Frontend]
- Invia chunks risposte via WebSocket
- Frontend visualizza risposta incrementale
- Mostra link sorgente cliccabili
Output: {answer, citations: [{doc_id, page, url}], tokens_used: N}
Streaming e Caching:
- Embedding query: Archiviati in cache Redis (10 min TTL)
- Risposte LLM: Non archiviati (troppo specifici alla sessione)
- WebSocket streaming: Invia via NestJS connected client
**Workflow 3: Document Deletion & Cleanup**
Quando un documento è marcato per eliminazione:
Input: {document_id}
1. [Check References]
- Verifica se nel chat history
- Se usato di recente, avvisa admin
2. [Delete from Qdrant]
- Query per tutti vector_id con document_id
- Cancella lotti da Qdrant
3. [Delete from PostgreSQL]
- Soft-delete record documento
- Soft-delete chunk text
- Mantieni chat history (immutabile)
4. [Update Indexes]
- Se necessario, ri-trigger rebuild indice
5. [Audit Log]
- Registra cancellazione con user_id, timestamp
Output: {vectors_deleted: N, chunks_deleted: N}
Struttura Nodo n8n Personalizzata
Mentre n8n fornisce nodi built-in per HTTP, database ecc., il sistema RAG usa nodi personalizzati per operazioni specializzate:
// Esempio: Custom Node - PDF Extract
// File: nodes/PdfExtractNode.ts
export class PdfExtractNode implements INodeType {
description: INodeTypeDescription = {
displayName: 'PDF Extract (Unstructured)',
name: 'pdfExtract',
group: ['transform'],
version: 1,
description: 'Extract text from PDF using Unstructured.io',
inputs: ['main'],
outputs: ['main'],
properties: [
{
displayName: 'File Path',
name: 'filePath',
type: 'string',
required: true,
placeholder: '/storage/uploads/doc.pdf',
},
{
displayName: 'Strategy',
name: 'strategy',
type: 'options',
options: [
{ name: 'Auto', value: 'auto' },
{ name: 'OCR', value: 'ocr' },
{ name: 'Fast', value: 'fast' },
],
default: 'auto',
},
],
};
async execute(
this: IExecuteFunctions,
): Promise<INodeExecutionData[][]> {
const filePath = this.getNodeParameter('filePath', 0) as string;
const strategy = this.getNodeParameter('strategy', 0) as string;
try {
const response = await axios.post(
'https://api.unstructured.io/general/v0/general',
{ file_path: filePath, strategy },
);
const extractedText = response.data.elements
.map((el: { text: string }) => el.text)
.join('\n');
return [[{ json: { text: extractedText, page_count: response.data.page_count } }]];
} catch (error) {
throw new NodeOperationError(
this.getNode(),
`PDF extraction failed: ${error.message}`,
);
}
}
}
Nodi Personalizzati Principali:
- PDF Extract: Parsing PDF con fallback
- Text Chunker: Divisione intelligente con sovrapposizione
- FastAPI Batch Embed: Embedding batch con retry
- Qdrant Vector Store: Inserimento vettori con metadati
- LLM Router: Sceglie OpenAI/Gemini/Ollama basato su configurazione
- Citation Parser: Estrae riferimenti dalla risposta
Monitoraggio e Debugg
n8n fornisce strumenti di debug eccellenti nel browser:
- Visualizzazione Workflow: Visualizza l'intero flusso, evidenzia nodi in esecuzione
- Data Inspector: Clicca su qualsiasi nodo, visualizza dati input/output
- Test Workflow: Simula esecuzione con dati fake, ispeziona risultati passo after passo
- Error Logging: Mostra errori esatti, stack trace, suggerimenti retry
- Execution History: Visualizza tutte le esecuzioni workflow, tempi, risultati
Dashboard Monitoraggio Customizzato:
Per gestire in scala è essenziale monitoraggio esterno:
- Prometheus espone metriche n8n: esecuzioni/min, duration, errori
- Grafana dashboard visualizza throughput, latenza, tasso di errore per workflow
- Alert su Slack se un workflow fallisce 3x consecutivamente
Configurazione e Deployment
n8n è distribuito come contenitore Docker con PostgreSQL backing store per i workflow:
version: '3.8'
services:
n8n:
image: n8nio/n8n:latest
ports:
- "5678:5678"
environment:
N8N_HOST: n8n.example.com
N8N_PROTOCOL: https
N8N_PORT: 5678
N8N_SECURE_COOKIE: 'true'
DB_TYPE: postgresdb
DB_POSTGRESDB_HOST: postgres
DB_POSTGRESDB_PASSWORD: ${DB_PASSWORD}
N8N_WEBHOOK_TUNNEL_URL: https://n8n.example.com/
N8N_EXECUTIONS_DATA_PRUNE: 'true'
N8N_EXECUTIONS_DATA_MAX_AGE: 259200 # 3 days
volumes:
- n8n_storage:/home/node/.n8n
depends_on:
- postgres
Scalabilità Orizzontale:
- Worker separati per esecuzioni lunghe (ingestion documenti multipli)
- Coda Redis per distribuire lavoro tra istanze n8n
- Concurrenza limitata per non sovraccaricare FastAPI/Qdrant
Best Practice per Workflow RAG
- Idempotenza: Ogni nodo dovrebbe essere safe di re-esecuzione. Qdrant /upsert usa ID, non duplica.
- Timeout Realistico: Embedding PDF di 100 pagine = > 10 minuti. Non aspettare 30 secondi e dare up.
- Fallback Chain: Se Unstructured API non disponibile, fallback a PyPDF locale.
- Logging Strutturato: Ogni nodo registra step, dimensione batch, latenza. Aiuta con debugging.
- Rate Limiting: Limita batch embedding, non inondare FastAPI.
- Soft Deletes: Non cancellare veramente vettori, marcare come deprecati (audit trail).
Prossimi Passi
Nel prossimo articolo, immergiamoci in Qdrant e Embeddings Vettoriali — come funziona la ricerca semantica, come scegliere modelli di embedding, e come ottimizzare la rilevanza.